We use a lot of APIs. Payment service provider? That’s an API. Warehouse? Orders automatically going to accounting? APIs. And many more. So at HYPER we’ve gotten a lot of experience working with them. Recently we were at the Mage Unconference. There was a panel about API best practices in which we contributed. We also left with some new ideas from other experts in the field. We’d love to share some of these best practices with you.

The nightmare scenario
Imagine the following happening in your shop: A customer visits your webshop, finds a product they like and places an order. They pay for it, and then… A blank page. Oh dear! They click around a bit and their cart is empty. They didn’t get any email about their order. But when they check with their bank, they did pay you.
They contact your customer service team and they look into the issue. Customer service finds that the order is stuck at pending payment. Check in with the payment service provider – oh yeah it’s paid. So they process the order manually, but your customer isn’t very happy.
Where did it go wrong? Well, as it turns out that after the successful payment, as per usual some data was sent to a marketing API, but their server was down for maintenance. Because their server was down your webshop waited for a while to send the data which resulted in the order getting stuck.
Get some REST at night
The big theme in our API best practices is that the external API is always uncertain. There are so many different things to worry about, for example:
- The external service might be down, for maintenance, natural disaster or something else.
- Your API token or password expired which means that you can’t connect.
- You’re rate-limited because you’ve been making too many API calls.
- The API is working but it’s slow, maybe much slower than you expected.
- They changed the format of data that returns.
- They got hacked and the data that returns is now dangerous.
- The API company raised their prices 300% and you want to switch to the API of their competitor. But the competitor’s API works a little differently.
All these kinds of risks can occur, but not using APIs isn’t an option either. So we need defences to make sure we can handle the risks. We use five layers of defence. Now let’s look at each of these five in detail.
Jump right to your favorite defence:
- 1st defence: Making a connection
- 2nd defence: Mapping raw data to valid Magento & business data
- 3rd defence: Using interfaces
- 4th defence: The time is right
- 5th defence: Preparing for trouble
1st defence: Making a connection
The connection module is super important, since without a connection the API is useless. We will not connect to the API from many different places in our application. If the API changes for some reason, we’d have to fix many parts in our application. Instead, we use one module that handles all requests to that API. If the way of connecting to the API changes, we only need to make changes in one place.

As said, in the module we handle all the logistics of the API:
- Connect using REST (popular), GraphQL (becoming more important) or SOAP (many legacy systems).
- Handle authentication (API keys, username/password, etc.).
- Retry if the request fails (a couple of times, but know when to give up).
- Slow down if we run up against rate limits.
- Collect results over multiple requests, if we need a lot of data and the API works page by page.
These are all a little bit different for each API, but tend to be the same for most services offered by one particular API. By bundling this all in one spot, we’d only have to make it work smoothly once and then we can re-use it for new tasks. Which also saves time!
2nd defence: Mapping raw data to valid Magento & business data
This is where (most of) the magic happens. We start with the raw data that comes from the API, and turn it into Magento data that is easy to understand and safe to use for the rest of our application (and for our developers of course).
When we get data from an API, it’s going to be in a format that makes sense to the company providing that API. Maybe they use USA style date formatting (month, day, year) while we use EU style formatting (day, month, year). Okay, so we have to transform (‘map’) that data. Well, we don’t want to do that everywhere through our application, since we’re likely to get it wrong somewhere. It is much easier to work out of one central module that maps all the data from the API before it gets distributed to the rest of our application.
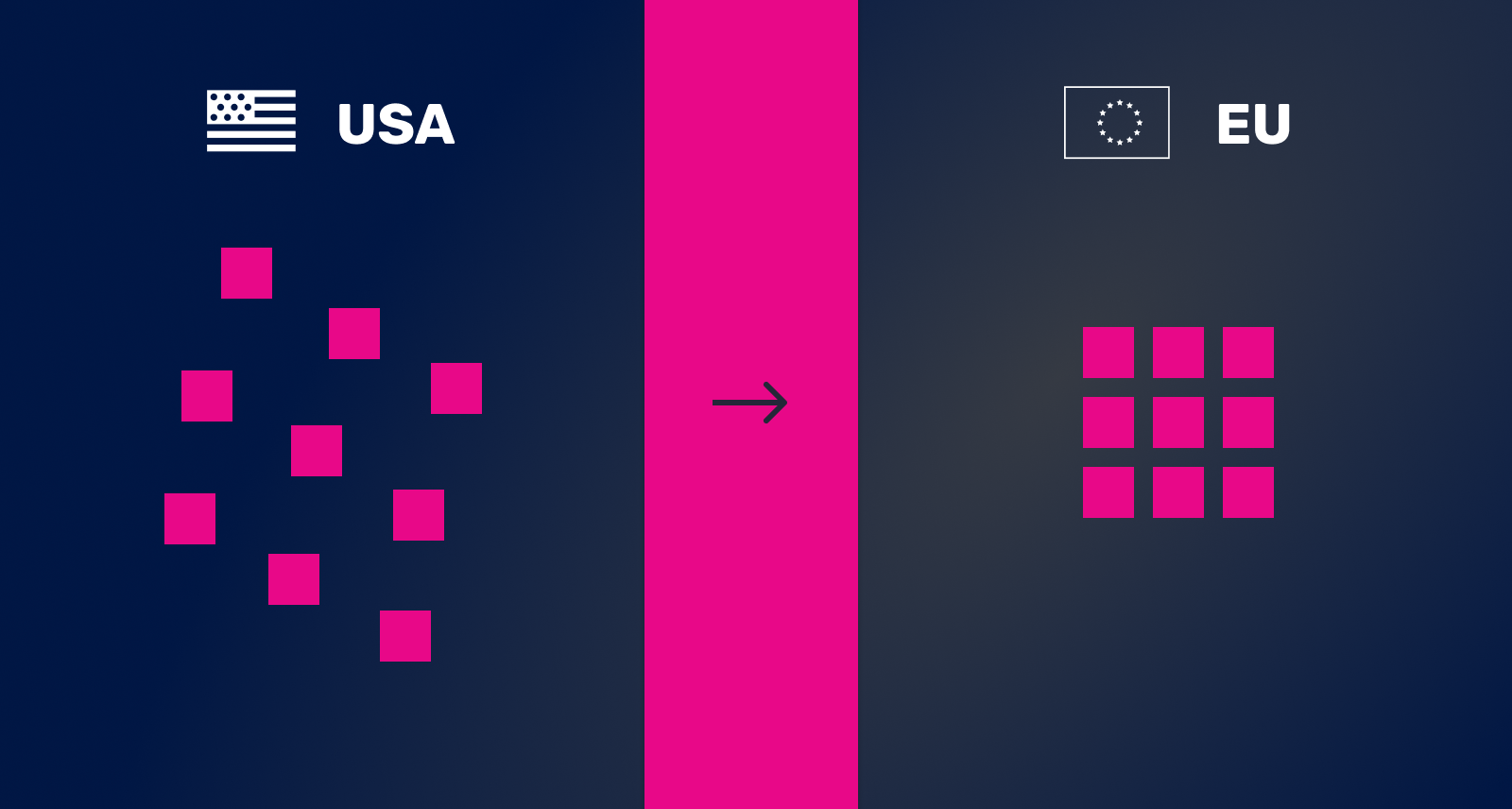
There are three specific problems which occur. We explain them a little bit further.
A useful format
The external API might return data as a JSON object, as an array or just as flat text. But this is annoying to handle in the rest of our application. We have to remember exactly what each field is called and where it’s located in the foreign data structure. We can do that way better!
So we created a so-called Value Object. This is a really simple object that just holds the data, but it has strict variable types. This way we always know what kind of form (text, number, date..) each aspect of the data is going to be, and so we know what that data is going to be called. The moment when we’re putting the raw data from the API into the Value Object is also the moment when we can transform it. For example, we do the checks to make sure all the dates are stored in ISO standard format.
When our colleague wants to work with the data the next day, they don’t have to ask us exactly how the API works. They see this data object with clearly labelled properties and can directly use them. For example this object represents a purchase that has a getPurchasedAtISODate() method. They know when they use the object, they’re going to get an ISO date. And if they see the getOrderedQty() method, they know that’s going to return a number.
Valid data
This is the moment to validate whether the data is in a healthy state. If a field is supposed to hold an email address, is that piece of text that we got from the API actually an email address? Is this person’s name safe to store in the database, or does it contain malicious code that could drop all tables?
If the data isn’t valid, we could decide to reject it completely, or attempt to fix or mark it. Since all API results go through this stage, everything gets checked. Once we’ve finished validating, our Value Object is guaranteed to be safe to use for the rest of the application. For example, we can trust that getOrderedQty() won’t give us a negative number.
Missing data
Sometimes an API doesn’t return anything, nada, nothing. This could be because the connection failed, because we contacted the wrong part of the API, or because their system is having trouble. And sometimes we get nothing without there being any kind of error. Maybe we were asking for a selection of products in a price range, but the company doesn’t have any, so we get an empty list back.
We can handle this in a couple of different ways, but the main point is to always plan ahead for it.
3rd defence: Using interfaces
Using interfaces means we’d have a standard for what the mapped data should look like, regardless of where it originated from. Even if we got our data sometimes from one API, and another time from the API of a competitor, we could use it the same way in our shop.
Interfaces are a PHP feature, although most modern programming languages have something similar. The basic idea is that you have a “contract” for what a particular value object can do for you. How it does that under the hood, isn’t important to you.
For example, we have a module that shows shop reviews in the shop’s header. Our clients can contract with a variety of firms that collect reviews, like Kiyoh and Trustedshops. They might even have a contract with different firms for the Dutch and German market. But we don’t want to write a different module for each of them. In the end, we’re just going to show mostly the same block on the frontend, showing either a “x out of 5 stars” or “x out of 10”. Where x should be a nice high number of course.
By using an interface, we can have one review module that we can use everywhere, and it can consult an “average review” interface to get a score. The frontend developer doesn’t have to worry about which review service is providing that score on the backend and how exactly it’s done.
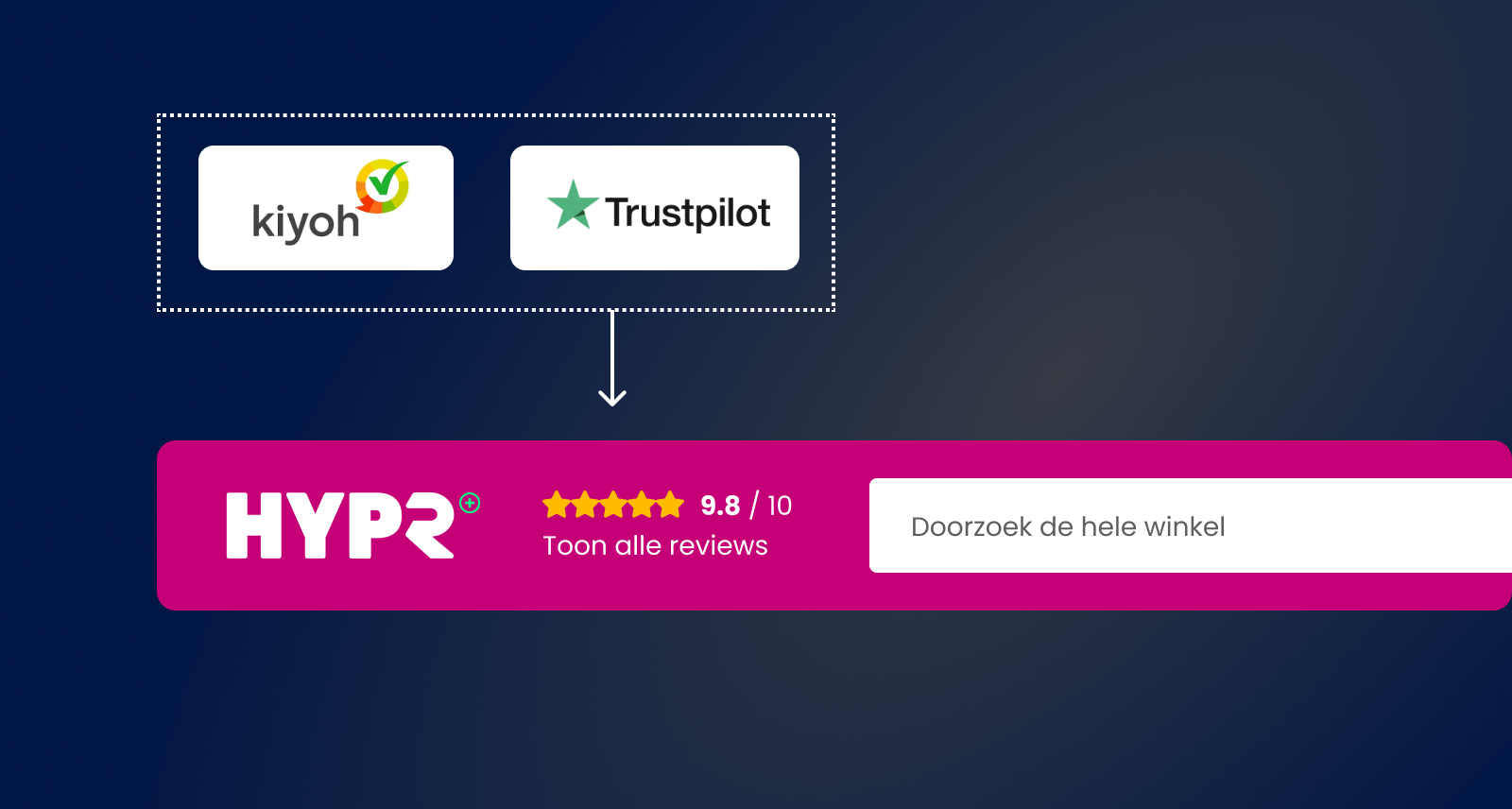
Putting this together, we now have the first three layers of defence. Each different API needs a separate connection module; and a separate mapping module. But all the APIs for a particular kind of business need can and should use the same interface, so we can swap out who we do business with. If we change partners, we don’t have to change the rest of our application, only those specific API modules. The rest of the application relies on the standardised interface.
4th defence: The time is right
We want all the fancy things that APIs can bring us. When do we need these API results? How badly do we need them? But what is the cost? The biggest cost is often time. A connection with the payment service provider is critical, we absolutely need to know if the customer has paid or not. But attributing a conversion to an ad service is also important, but not critical.
The first thing to ask is: how important is this API call? And the second question is, how important is it to do this API call right now?
Suppose we want to offer some kind of promotion to returning customers. When they login to their account, there’s a connection to a marketing API thinking about what we should offer this returning customer. Meanwhile, the customer is annoyed that logging in takes so long. Not good. And not necessary.
Synchronous and asynchronous calls
In our example we made the customer wait for the result of the API call; this is called handling it synchronously. But we could have also done something else. We could have put a task on a separate process to get that API data, and meanwhile let the customer continue with logging in. When we get data back from the API, we’ll show it to the customer then. This is called handling it asynchronously.
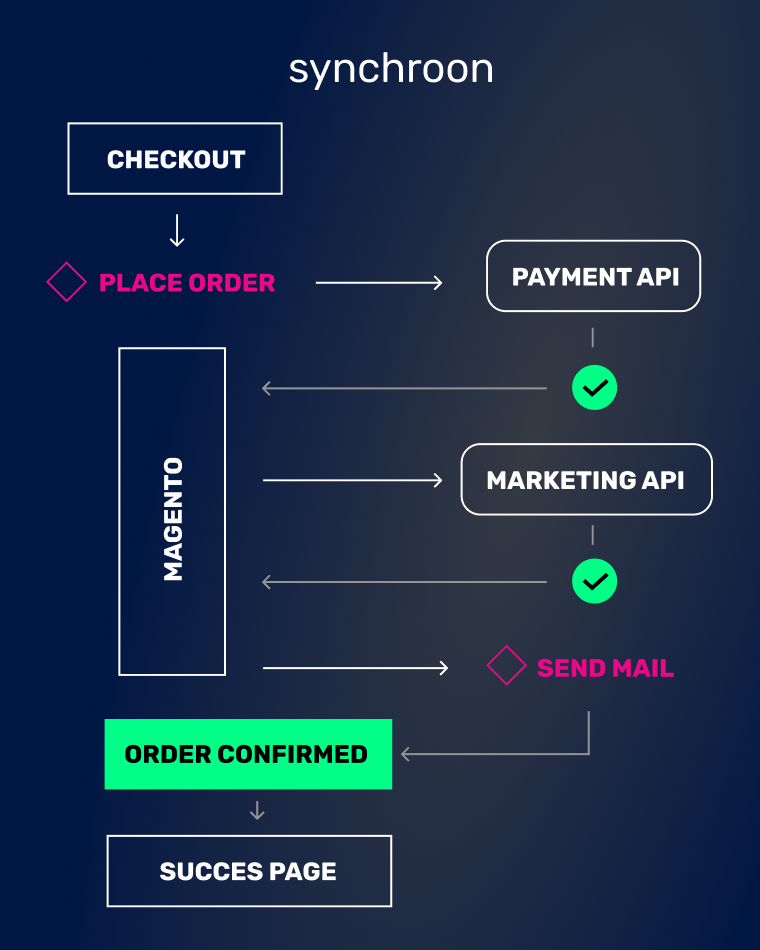
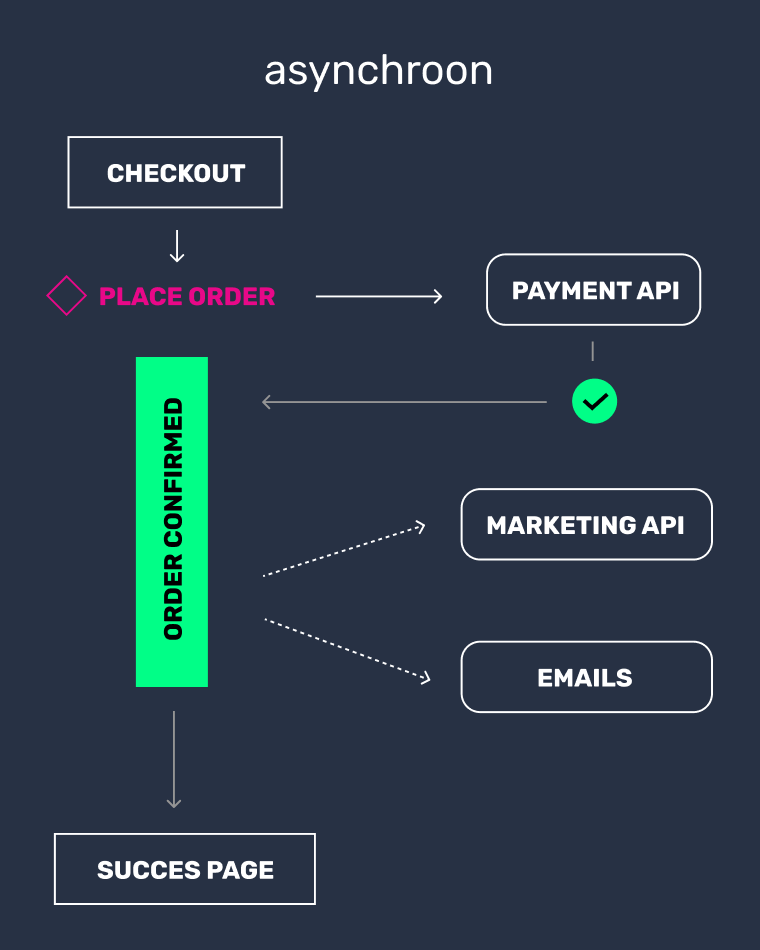
You have to consider for each API call whether we have to wait for it, or if we can get it later. For example, the API call to the payment service provider is worth waiting for, since otherwise we have to just guess whether the customer paid. So asynchronous API calls aren’t always the best choice.
Coming back to the first question: how important is this API call? The API is an external system and it might just not work sometimes. If it doesn’t work at first, how long do we keep retrying? When do we give up? And what happens then?
If we can’t attribute a conversion to an ad service, we’re not going to tell the customer they’re not allowed to place the order. We’d like to do the attribution (to stay on good terms with the ad service..) but it’s not critical. Getting the customer to pay is critical. If we can’t confirm if the customer paid, we don’t want to ship.
So for each API call, you need to think about when to give up, and what to do then.
5th defence: Preparing for trouble
We’re doing something with an API and for some reason it doesn’t work. Trouble is going to happen someday, you can’t anticipate and control everything. But you can be prepared and make it much easier to figure out what’s going wrong, who’s been affected, and how to recover. For this we tend to rely on two approaches: good logs, and good exceptions.

Logging
A popular principle in programming is YAGNI: You Ain’t Gonna Need It. But there are some things that you somehow always end up needing and wishing you’d built in from the start. Logging is most definitely one of them. If something happens and you don’t have your logs, you can’t go back and decide to have them.
Logging needs to be specific: “The product couldn’t be found” doesn’t tell you much. “Product with ID 123 couldn’t be found” is more helpful. A useful log should make it easy to find out:
- What happened?
- Where in the code did it happen? (“Why” did it happen?)
- When did it happen?
- How often did it happen?
- Who/what did it happen to?
It’s a bit like journalism or detective work. And just like those, you also have to be careful with peoples’ personal information. Just like you’re not supposed to put someone’s home address in the newspaper, you should be careful with what kind of data you log. There’s a tension here: you want to have a lot of information to help you figure out problems, but you also don’t want to overdo it.
So the big rule for logging is: log specific things. Specific to be useful, and specific not to accidentally log too much.
Exceptions
As we know by now, sometimes things can go wrong in the API. A connection fails, or the data is invalid. The function handling that is just there to do that one thing, it doesn’t know how to handle the abnormal situation. So it throws an “exception”, because it can’t continue the normal run of the program.
Just like logging, exceptions should be specific. If your data is valid, don’t throw a generic exception, throw a ValidationException. Then another piece of code that knows how to deal with invalid data can catch that exception, and present the customer with useful feedback on what to do.
Catching exceptions should also be specific. Especially in poor quality modules, you’ll see code that tries something risky, catches all exceptions that could happen and quietly throws them away. But this can prevent another piece of code from receiving the exception, that knows how to handle that specific exception you threw. So don’t be that programmer. Catch only the exceptions you actually have a clue about. (Example: I recently spent four hours trying to figure out why a shipping method didn’t work for evening delivery. It turned out that there was a poorly named checkbox that needed to be ticked. But the error message saying what was wrong was caught and dropped.)
With one exception (pun intended): the connection to the API. Stuff might go wrong on the far end that causes an exception on your side. So your connection module that’s really close to the actual call to the API, should catch all those mysterious external errors and convert them into your own exceptions of a specific type that you do know.
Conclusion
Using APIs is great, but it also brings a lot of challenges. By implementing these five best practices, we can better manage a lot of challenges. Streamlined connectivity, correct data mapping, use of interfaces, careful timing of API calls and preparation for problems are the key points of successful API use. This approach allows us to maximise the benefits of APIs while minimising risks. Not quite getting there? We can help you with links and integrations.