We gebruiken veel APIs. Payment service provider? Dat is een API. Het magazijn? Orders die automatisch naar de boekhouding gaan? Allemaal APIs. En er is nog zoveel meer. Bij HYPER hebben we veel ervaring met het werken ermee. Onlangs waren we op de Mage Unconference. Daar was een panel over API best practices waaraan wij hebben bijgedragen. Daarnaast zijn we naar huis gegaan met een aantal nieuwe ideeën van andere experts op dit gebied. We willen graag een aantal van deze best practices met je delen.

Worst case scenario
Stel je voor dat het volgende gebeurt in jouw winkel: Een klant bezoekt je webshop, vindt een product dat hij of zij leuk vindt en plaatst een bestelling. Ze betalen en dan… Een lege pagina… Ah nee! Ze klikken wat rond en hun winkelwagen is leeg. Ze hebben geen e-mail ontvangen over hun bestelling. Maar als ze hun afschriften controleren, blijken ze wel betaald te hebben.
De klant neemt contact op met je klantenserviceteam en zij onderzoeken waar het fout ging. De klantenservice komt erachter dat de bestelling is blijven steken op ‘In afwachting van betaling’. Na een korte check bij de betalingsprovider komen ze er snel achter dat de bestelling wel betaald is. Dus jouw team verwerkt de bestelling dan maar handmatig, maar je klant is niet erg blij. Logisch.
Waar ging het mis? Nou, het blijkt dat er na de succesvolle betaling gegevens naar een marketing API zijn gestuurd, wat gebruikelijk is. Echter werkte de server van de API niet in verband met onderhoud. Omdat hun server niet bereikbaar was, heeft de webshop een tijdje gewacht met het verzenden van de gegevens, waardoor uiteindelijk de bestelling vastliep.
Geen zorgen voor de REST
Het overkoepelende thema bij onze API best practices is dat de externe API eigenlijk altijd onzeker is. Er zijn zoveel verschillende dingen om je zorgen over te maken, bijvoorbeeld:
- De externe service kan down zijn, voor onderhoud, een natuurramp of iets anders.
- Je API token of wachtwoord is verlopen, wat betekent dat je geen verbinding kunt maken.
- Je hebt een beperking omdat je te veel API calls hebt gedaan.
- De API werkt, maar is traag. Misschien wel veel trager dan je had verwacht.
- Ze hebben de gegevensformaat die terugkomt veranderd.
- Ze zijn gehackt en de gegevens die terugkomen zijn nu gevaarlijk.
- De leverancier verhoogt de prijzen en je wilt overstappen naar de API van de concurrent. Maar die API werkt een beetje anders.
Al dit soort risico’s kunnen zich voordoen, maar geen APIs gebruiken is ook niet een optie. We hebben dus verdedigingsstrategieën nodig om ervoor te zorgen dat we de risico’s aankunnen. We gebruiken vijf verschillende strategieën, elk leggen we iets verder uit.
Navigeer direct naar jouw favoriete verdediging:
- 1e verdediging: Een connectie maken
- 2e verdediging: Ruwe gegevens mappen naar geldige Magento & bedrijfsgegevens
- 3e verdediging: Interfaces gebruiken
- 4e verdediging: De tijd is rijp
- 5e verdediging: Voorbereiden op problemen
1e verdediging: Een connectie maken
De connectie module is super belangrijk, want zonder verbinding is een API nutteloos. We zullen niet op veel verschillende plaatsen in onze applicatie verbinding maken met de API. Als de API om de een of andere reden veranderd, zouden we op veel plekken in onze applicatie reparaties moeten uitvoeren, onhandig. In plaats daarvan gebruiken we één module die alle verzoeken van die API afhandelt. Als de verbinding met de API verandert, hoeven we maar op één plaats wijzigingen aan te brengen.

In deze module behandelen we alle aspecten van de API, zoals:
- Verbinding maken via REST (populair), GraphQL (steeds belangrijker) of SOAP (veel legacy systems).
- Authenticatie afhandelen (API-keys, gebruikersnaam/wachtwoord, enz.).
- Opnieuw proberen als het verzoek mislukt (een aantal keer, maar weet wanneer op te geven).
- Vertragen wanneer we tegen limieten aanlopen.
- Resultaten verzamelen over meerdere verzoeken, als we veel gegevens nodig hebben en de API pagina voor pagina werkt.
Voor elke API is dit net weer anders, maar zo goed als hetzelfde voor de meeste diensten die door een bepaalde API worden aangeboden. Door dit allemaal op één plek te bundelen, hoeven we het maar één keer soepel te laten werken en kunnen we het daarna hergebruiken voor nieuwe taken. Dat bespaart ook tijd!
2e verdediging: Ruwe gegevens mappen naar geldige Magento & bedrijfsgegevens
This is where (most of) the magic happens! We beginnen met de ruwe gegevens die van de API komen en transformeren deze om die gemakkelijk te begrijpen en veilig te gebruiken Magento gegevens voor de rest van onze applicatie (en voor onze ontwikkelaars natuurlijk).
Wanneer we data van een API ontvangen kan het een formaat hebben dat logisch is voor het bedrijf dat de API levert. Misschien gebruiken zij USA datumopmaak (mm/dd/yyyy) terwijl wij EU opmaak gebruiken (dd/mm/yyyy). Oké, dus we moeten die gegevens transformeren (‘mapping’). We willen dat niet overal in onze applicatie doen, omdat het dan waarschijnlijk ergens fout gaat. Het is veel eenvoudiger om vanuit één centrale module te werken die alle gegevens van de API in kaart brengt voordat ze naar de rest van onze applicatie worden gedistribueerd.
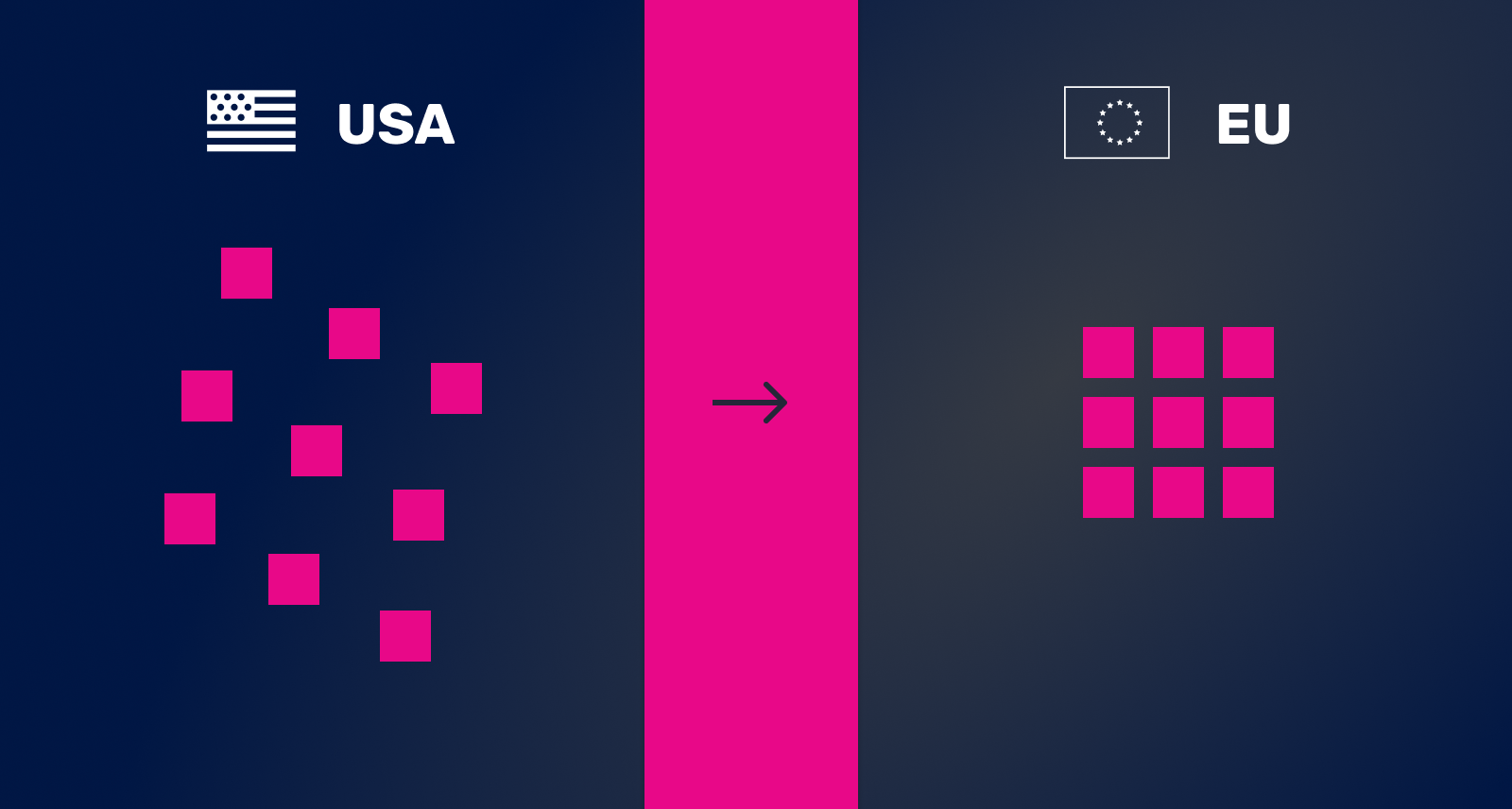
Er zijn drie specifieke problemen die zich vaker voordoen, we leggen ze kort uit:
Een nuttig formaat
De externe API kan gegevens retourneren als een JSON object, als een array of gewoon als platte tekst. Maar dit is vervelend om te verwerken in de rest van onze applicatie. We moeten precies onthouden hoe elk veld heet en waar het zich bevindt in de vreemde gegevensstructuur. Dat kunnen we veel beter!
Dus hebben we een zogenaamd Value Object gemaakt. Dit is een heel eenvoudig object dat alleen de gegevens bevat, maar het heeft strict variable types. Op die manier weten we altijd wat voor soort vorm (tekst, nummer, datum…) elk aspect van de gegevens zal zijn, en dus weten we ook hoe die gegevens gaan heten. Het moment waarop we de ruwe gegevens van de API in het Value Object stoppen, is ook het moment waarop we het kunnen transformeren. We controleren bijvoorbeeld of alle datums zijn opgeslagen in het ISO-standaard formaat.
Als een collega de volgende dag met de data wilt werken, hoeft hij of zij ons niet te vragen hoe de API precies werkt. Ze zien dit dataobject met duidelijk gelabelde eigenschappen en kunnen deze direct gebruiken. Dit object vertegenwoordigt bijvoorbeeld een aankoop die een getPurchasedAtISODate() methode heeft. Ze weten dat als ze het object gebruiken, ze een ISO-datum krijgen. En als ze de methode getOrderedQty() zien, weten ze dat die een getal zal opleveren.
Geldige gegevens
Dit is hét moment om te valideren of de gegevens in een gezonde staat zijn. Als een veld een e-mailadres moet bevatten, is dat stukje tekst dat we van de API hebben gekregen dan ook echt een e-mailadres? Is de naam van deze persoon veilig om op te slaan in de database, of bevat het kwaadaardige code die alle tabellen kan laten vervallen?
Als de gegevens niet geldig zijn, kunnen we besluiten om ze helemaal te weigeren of om ze te corrigeren of te markeren. Aangezien alle API resultaten deze fase doorlopen, wordt alles gecontroleerd. Zodra we klaar zijn met valideren, zou ons Value Object gegarandeerd veilig moeten zijn om te gebruiken voor de rest van de applicatie. We kunnen er bijvoorbeeld op vertrouwen dat getOrderedQty() ons geen negatief getal zal geven.
Ontbrekende gegevens
Soms retourneert een API niets, nada, noppes. Dit kan zijn omdat de verbinding is mislukt, omdat we contact hebben opgenomen met het verkeerde deel van de API, of omdat hun systeem problemen heeft. En soms krijgen we niets terug zonder dat er een fout is opgetreden. Misschien vroegen we om een selectie van producten in een bepaalde prijsklasse, maar heeft het bedrijf dat niet, dus krijgen we een lege lijst terug.
We kunnen dit op verschillende manieren aanpakken, maar het belangrijkste is dat we hier altijd een plan voor maken!
3e verdediging: Interfaces gebruiken
Het gebruik van interfaces betekent dat we een standaard hebben voor hoe de in kaart gebrachte gegevens eruit moeten zien, ongeacht waar ze vandaan komen. Zelfs als we onze gegevens soms van de ene API krijgen en een andere keer van de API van een concurrent, kunnen we ze op dezelfde manier gebruiken in onze winkel.
Interfaces zijn een PHP-functie, hoewel de meeste moderne programmeertalen iets soortgelijks hebben. Het basisidee is dat je een “contract” hebt voor wat een bepaald data object voor je kan doen. Hoe dat onder de motorkap gebeurd, is niet belangrijk voor jou.
We hebben een module die winkelbeoordelingen toont in de header van de winkel. Onze klanten kunnen contracten afsluiten met verschillende bedrijven die beoordelingen verzamelen, zoals Kiyoh en Trustedshops. Ze kunnen zelfs een contract hebben met verschillende bedrijven voor de Nederlandse en Duitse markt. Maar we willen niet voor elk van hen een andere module schrijven. Uiteindelijk gaan we gewoon grotendeels hetzelfde blok op de voorkant laten zien, met een “x van de 5 sterren” of “x van de 10”. Waarbij x natuurlijk een mooi hoog getal moet zijn.
Door een interface te gebruiken, kunnen we één beoordelingsmodule hebben die we overal kunnen gebruiken en die een “gemiddelde beoordeling”-interface kan raadplegen om een score te krijgen. Het hoeft zich geen zorgen te maken over welke review service die score geeft.
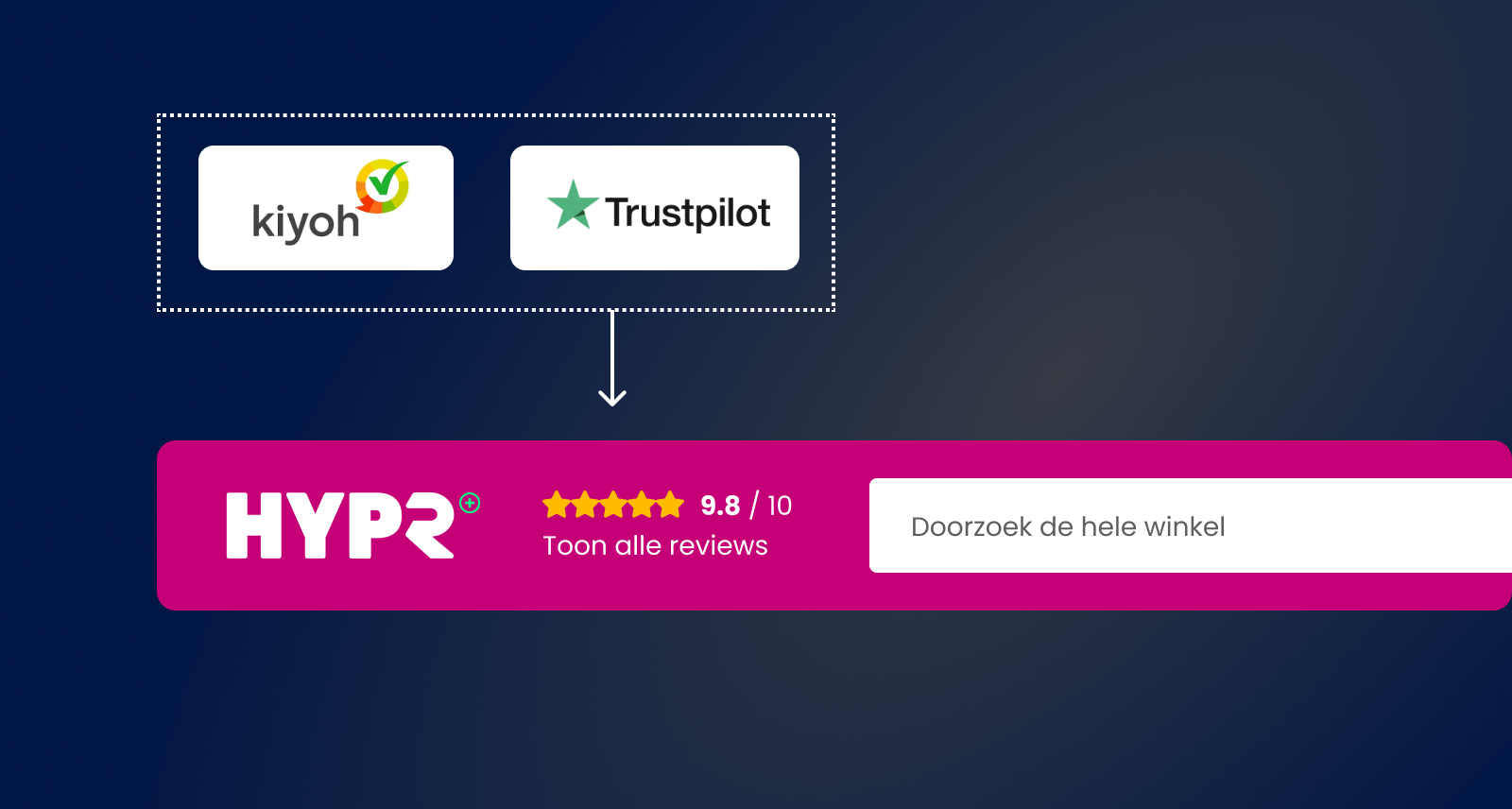
Als we dit samenvoegen, hebben we nu de eerste drie verdedigingsstrategieën. Elke verschillende API heeft een aparte verbindingsmodule nodig en een aparte mapping module. Maar alle APIs voor een bepaald soort bedrijfsbehoefte kunnen en moeten dezelfde interface gebruiken, zodat we kunnen wisselen met wie we zaken doen. Als we van partner veranderen, hoeven we de rest van onze applicatie niet te veranderen, alleen die specifieke API-modules. De rest van de applicatie vertrouwt op de gestandaardiseerde interface.
4e verdediging: De tijd is rijp
We willen alle mooie dingen die APIs ons kunnen brengen. Wanneer hebben we deze API resultaten nodig? Hoe hard hebben we ze nodig? Maar wat zijn de kosten? De grootste kostenpost is vaak tijd. Een verbinding met de payment service provider is cruciaal, we moeten absoluut weten of de klant betaald heeft of niet. Maar een conversie toewijzen aan een advertentie service is ook belangrijk, maar niet kritisch.
De eerste vraag die we ons moeten stellen is: hoe belangrijk is deze API call? En de tweede vraag is: hoe belangrijk is het om deze API call nu te doen?
Stel dat we een soort promotie willen aanbieden aan terugkerende klanten. Wanneer ze inloggen op hun account, is er een verbinding met een marketing API die nadenkt over wat we deze terugkerende klant moeten aanbieden. Ondertussen vindt de klant het vervelend dat het inloggen zo lang duurt. Dat is niet goed. En niet nodig.
Synchroon en asynchroon aanroepen
In het voorbeeld hebben we de klant eerst laten wachten op het resultaat van de API call; dit heet synchroon afhandelen. Maar we hadden het ook iets anders kunnen doen. We hadden een taak op een apart proces kunnen zetten om die API gegevens op te halen, en ondertussen de klant door kunnen laten gaan met inloggen. Als we dan gegevens terugkrijgen van de API, laten we die aan de klant zien. Dit heet asynchroon afhandelen.
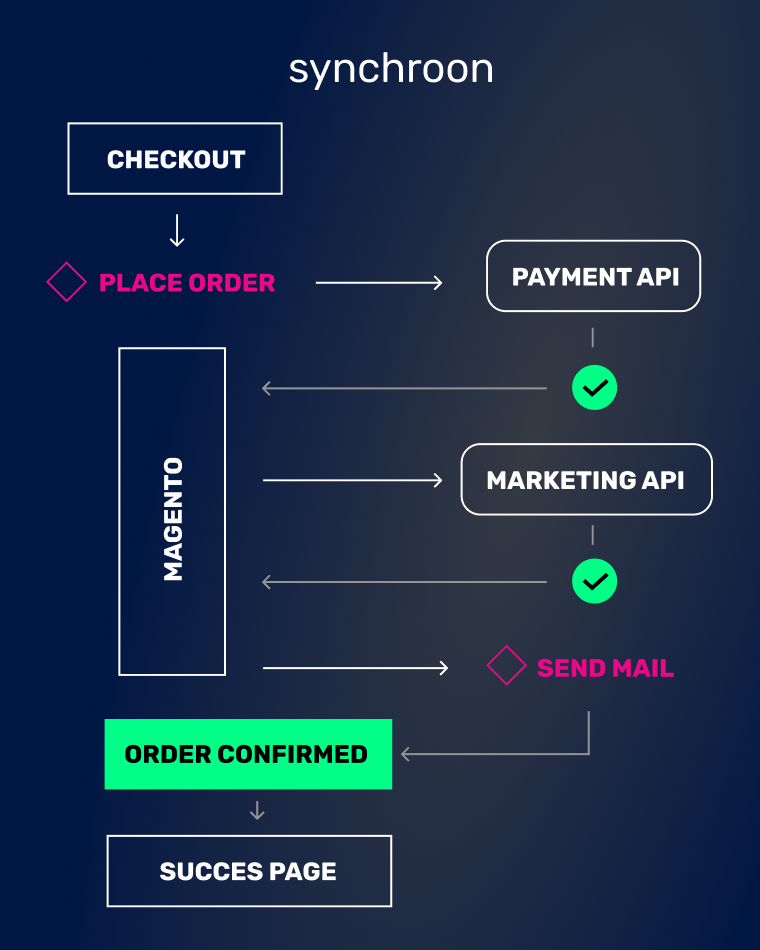
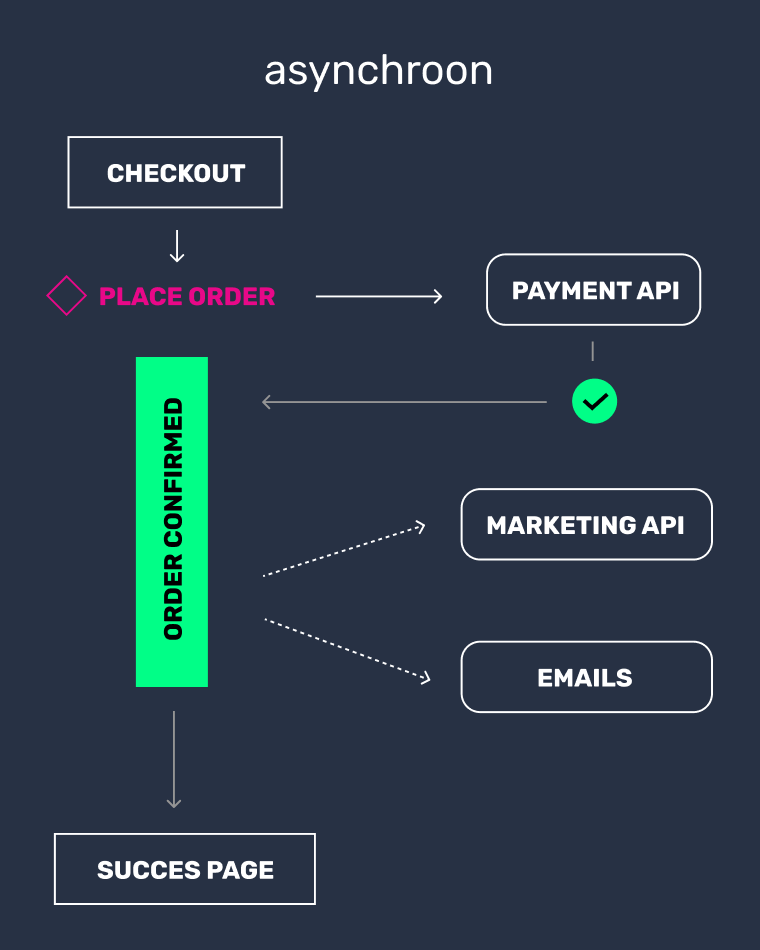
Je moet voor elke API call overwegen of we erop moeten wachten, of dat we het later kunnen krijgen. Bijvoorbeeld, de API call naar de payment service aanbieder is het waard om op te wachten, omdat we anders gewoon moeten gokken of de klant betaald heeft. Asynchrone API calls zijn dus niet altijd de beste keuze.
Terugkomend op de eerste vraag: hoe belangrijk is deze API call? De API is een extern systeem en soms werkt het gewoon niet. Als het eerst niet werkt, hoe lang blijven we het dan opnieuw proberen? Wanneer geven we het op? En wat gebeurt er dan?
Als we een conversie niet kunnen toeschrijven aan een advertentie, gaan we de klant niet vertellen dat hij of zij de bestelling niet mag plaatsen. We willen de attributie graag doen (om op goede voet te blijven met de advertentieprovider) maar het is niet cruciaal. De klant laten betalen is cruciaal. Als we niet kunnen bevestigen of de klant heeft betaald, willen we niet verzenden.
Dus voor elke API call moet je bedenken wanneer je opgeeft en wat je dan moet doen.
5e verdediging: Voorbereiden op problemen
We doen iets met een API en er loopt iets mis. Het gaat een keer gebeuren, je hebt nooit alles in de hand. Maar je kan wel voorbereid zijn en het veel gemakkelijker maken om uit te zoeken wat er aan de hand is, wie er getroffen is, en hoe je kunt herstellen. Hiervoor maken we gebruik van twee technieken: logs en exceptions (“uitzonderingen”).

Loggen
Een populair principe in programmeren is YAGNI: You Ain’t Gonna Need It. Maar er zijn een paar dingen die je op de een of andere manier altijd nodig hebt en waarvan je zou willen dat je ze vanaf het begin had ingebouwd. Loggen is daar zeker één van. Als er iets gebeurt en je hebt je logs niet, dan kun je niet terug om ze te veranderen.
Logging moet specifiek zijn: “Het product kon niet worden gevonden” zegt niet veel. “Product met ID 123 kon niet worden gevonden” is heb je meer aan. Een bruikbaar logboek maakt het mogelijk om erachter te komen:
- Wat is er gebeurd?
- Waar in de code is het gebeurd? (“Waarom” is het gebeurd?)
- Wanneer is het gebeurd?
- Hoe vaak is het gebeurd?
- Wie of wat is er getroffen?
Het is een beetje als journalistiek of detectivewerk. En net zo, moet je voorzichtig zijn met persoonlijke informatie. Je kunt iemand zijn adres niet zomaar in de krant zetten, en je moet ook opletten welke informatie je logt. Daar zit een spanning in: je wilt zoveel mogelijk informatie hebben om problemen uit te zoeken, maar je moet ook niet te ver gaan.
Dus de belangrijkste regel voor loggen is: log specifieke dingen. Specifiek om nuttig te zijn, en specifiek om niet per ongeluk te veel te loggen.
Exception
Zoals we inmiddels weten, kunnen er soms dingen misgaan met de API. Een verbinding mislukt, of de gegevens zijn ongeldig. De functie die dat afhandelt is er alleen om dat ene ding te doen, het weet niet hoe het met de abnormale situatie om moet gaan. Dus werpt het een uitzondering (een “exception”) op.
Net als bij loggen, moeten uitzonderingen specifiek zijn. Als je gegevens geldig zijn, werp dan een algemene exception op, maar een ValidationException. Dan kan een ander stuk code dat weet hoe om te gaan met ongeldige gegevens deze opvangen en de klant nuttige feedback geven over wat te doen.
Het vangen van uitzonderingen moet ook specifiek zijn. Vooral in modules van slechte kwaliteit zie je code die iets riskants probeert, alle uitzonderingen vangt die zouden kunnen gebeuren en ze stilletjes weggooit. Maar daardoor kan het gebeuren dat een ander stuk code dat bedoeld was om die specifieke uitzondering af te handelen, de uitzondering niet meer ontvangt. Wees dus niet zo’n developer. Vang alleen de uitzonderingen waar je echt verstand van hebt. (Voorbeeld: ik ben vier uur bezig geweest met uitzoeken waarom een verzendmethode geen avondlevering kon doen. Het bleek dat er ergens een vinkje moest worden gezet op een plek waar je dat niet verwacht. Maar de foutmelding die je dat vertelde, werd op deze manier ingeslikt.)
Met één uitzondering (pun intended): de verbinding met de API. Er kunnen dingen misgaan aan de andere kant die een uitzondering aan jouw kant veroorzaken. Dus je verbindingsmodule die heel dicht bij de eigenlijke aanroep naar de API zit, moet al die mysterieuze externe fouten opvangen en ze omzetten in je eigen uitzonderingen van een specifiek type dat je wel kent.
Conclusie
Het gebruik van API’s is geweldig, maar brengt ook veel uitdagingen met zich mee. Door deze vijf best practices te implementeren, kunnen we veel uitdagingen beter het hoofd bieden. Gestroomlijnde connectiviteit, correcte data mapping, gebruik van interfaces, zorgvuldige timing van API call en voorbereiding op problemen zijn de belangrijkste punten van succesvol API gebruik. Met deze aanpak kunnen we de voordelen van APIs maximaliseren en tegelijkertijd de risico’s minimaliseren. Kom je er niet helemaal uit? Wij kunnen je helpen met koppelingen en integraties.